「度天隊長」聊天機械人的深度學習之旅
「度天隊長」聊天機械人的深度學習之旅
林沁宜
2022年10月
上回向大家解釋了聊天機械人「度天隊長」是如何煉成的,不知道大家還有印象嗎?
自從我們的實習生「度天隊長」投入工作以來,煩惱越來越多。
例如同事說「你隻蘋果壞咗啊!」到底是水果變壞,還是手機壞了?
又或者「星期一就8號,星期三呢就10號!」到底是在說日子,還是熱帶氣旋警告信號呢?
深度學習的領域日新月異。「度天隊長」發現,原來自己的判斷模式依然有進步空間。
例如同事說「你隻蘋果壞咗啊!」到底是水果變壞,還是手機壞了?
又或者「星期一就8號,星期三呢就10號!」到底是在說日子,還是熱帶氣旋警告信號呢?
深度學習的領域日新月異。「度天隊長」發現,原來自己的判斷模式依然有進步空間。
「度天隊長」在收到輸入的問題後,會首先將句子進行分詞(tokenisation),然後根據電腦程式建立的語言模型(language model)為每一個詞語配對上一個被稱為embedding的向量(vector)。這些由純數字組成的embedding就有如我們所認知的「詞義」,代表著詞語的「特徵 (feature)」。
向量可以圖像化成有不同長度、指向不同方向的箭頭。假設意思相似的詞語會有相似的embedding向量,箭頭的長度方向也就越近似。由於向量有「可加可減機制」,極端來說,一個完美的語言模型能夠做到以下的計算:
<國王>-<男人>+<女人>=<女皇>
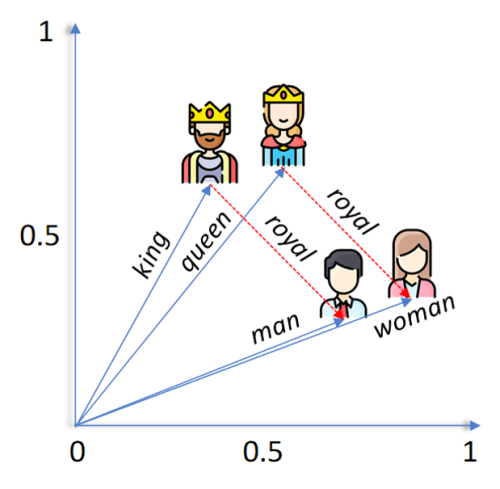
圖一 國王(king), 女皇(queen), 男人(man), 女人(woman)及皇室(royal)的向量示意圖。
要留意的是,在這個定義下,一個多義詞就會有多個可能的embedding。那如何分辨到底是日曆上的「8號」,還是颱風天的「8號」呢?這時候,就需要深度學習中的一個概念:注意力(attention)機制。
假設「6月8號會唔會掛8號波?」這句句子被分詞為:
6月 / 8號 / 會唔會 / 掛 / 8號 / 波 / ?
想知道前半的「8號」是甚麼意思,就需要注意「6月」這個詞語,因為他們都是形容日期或時間的。而後半的「8號」的詞義則與「掛」和「波」這兩個詞語更有關係,因為...你懂的。
於是,為了訓練一個可以反映出這些語意關聯的語言模型,「度天隊長」選擇了名為遮蔽語言模型(Masked Language Modelling)的方法。顧名思義,這個訓練方法會隨機遮蔽固定比例的詞語,然後計算同一句子中哪些詞語對於推算被遮蔽的詞語影響最大,需要投放更多「注意力」。 例如以下的訓練集:
6月 / 8號 / 會唔會 / 掛 / [MASK] / 波 / ?
幾時 / 掛 / [MASK] / 波 / ?
快啲 / 掛 / [MASK] / 波 / 啦 / !
就可以令模型學習到「掛」和「波」這兩個字對推斷被[MASK]遮蔽的詞語的embedding更有用,亦代表這些詞語的意思更有關連。(至於到底掛幾號波...嗯。)
而這種將目標詞語前後的文字都納入計算範圍的模式被稱為雙向編碼器(bidirectional encoder),也可以想像為我們所謂的前文後理。經過訓練後的語言模型,就可以根據整體的句子或文章,為分詞後的詞語配上更能準確代表其特徵的embedding。對「度天隊長」來說,就是他終於學會在不同前文後理的情況下,「8號」到底是哪個意思了。
其實換個角度解釋,遮蔽語言模型和填充題很類似。深度學習就是參考了人類的學習模式而發展的電腦演算法。也就是說,「度天隊長」需要更加「貼地」的訓練集,才能更好的理解用戶的查詢。
可是,重頭建立一個語言模型,動輒需要幾千萬的句子用作訓練,甚至可能要電腦運算超過一個星期。為了節省成本和時間,「微調(fine-tuning)」就成為了一個很好的選擇。 現在網絡上有很多開源(open source)的預訓練模型(pre-trained model)。這些語言模型以大量的數據集預先訓練好,對一般的句式、文法等一個有「基礎理解」。微調則是以這些預訓練模型作為基礎,只需要使用少量的訓練集,就可以在幾個小時內使模型學習到一些更專門的語法或詞語,例如廣東話和天文氣象的專有名詞。 打個比喻,如果重頭訓練語言模型就像教隻字不識的嬰兒讀這篇文章,那微調就像是你現在在讀這篇文章一樣。
在旅途中,「度天隊長」更發現有許多不同的深度學習方法,能訓練他成為可以對話的語音機械人。說不定,如果用上和遮蔽語言模型類似的學習方法,還可以讓他分辨同音字和多音字呢。 希望這場深度學習之旅早日修成正果,讓大家一起見證「升呢」的「度天隊長」!