聊天機械人「度天隊長」是如何煉成的?
聊天機械人「度天隊長」是如何煉成的?
李翰屏
2021年10月
天文台「度天隊長」聊天機械人服務於2020年2月推出,採用人工智能技術,自動回答一系列天氣或天文有關問題,如現時天氣、天氣警告、天氣預測、潮汐、香港標準時間、世界大城市天氣預測、日出日落時間等(圖一)。該服務自推出以來廣受歡迎,平均每月有接近12萬次對答,評分則有接近七成達4分或以上(5為滿分)。那麼, 這一個聊天機械人背後運作的原理是甚麼呢?「度天隊長」是如何理解和回應問題呢?
首先, 度天隊長會先對問題進行分類。天文台會預先準備一批問題的樣本和對話意圖(intent),然後運用電腦程式進行監督式學習(supervised learning) , 從而建立起一判斷模式(learning model)。
例如,天文台準備了一批與氣温有關的問題,如「銅鑼灣幾度?」、「幾度呀宜家?」、「熱唔熱?」等等,並標簽為「温度」類別。同樣,天文台會準備其他常見並與天文台服務相關的問題並事先歸類標簽,從而建立起一套訓練數據集。
為了提高訓練效率, 在這過程會用自然語言理解(natural language understanding)引擎中的中文分詞器(tokenizer)將問題作最合理的句子斷詞(tokenization)。
| 例如:「香港今日氣温如何?」這一問題可以有多種拆成不同標記(token) 的拆法 | ||
| (i) | [香][港][今][日][氣][温][如][何] | (一共7個標記) |
| (ii) | [香港今][日][氣温如何] | (一共3個標記) |
| (iii) | [香港今日氣][温如何] | (一共2個標記) |
| (iv) | [香港今][日氣温如何] | (一共2個標記) |
| (v) | [香港][今日][氣温][如何] | (一共4個標記) |
很明顯, 我們會採用第(v)種拆法, 因為在這種拆法下每一個標記都是有意義的。而如何進行斷詞的技術細節則視乎我們選用哪一種自然語言理解引擎。之後,我們通過使用一系列人工智能的電腦程式,用這一組已拆好詞語和已標記好類別的問題,即一套訓練數據集來建立一個問題類別判斷模式。
每當有問題查詢時,「度天隊長」會使用該判斷模式去找出這一個問題最有可能的數個類別,並以最高分者為該問題的類別。例如,有市民問「沙田今日幾度?」,「 度天隊長」會先找出問題的斷詞, 再運用預先準備好的判斷模式,找出該問題與各類別相關程度的分數,最高分數的類別會是該問題的類別:
| 「沙田今日幾度?」 --> [沙田][今日][幾][度] | |
| 類別: | 分數 |
| (1) 「温度」: | 99.99…分 |
| (2) 「與天氣無關」: | 0.00… 分 |
| (3) 「日出、日落」: | 0.00… 分 |
| (4) .... | |
因為"温度"最高分,所以度天隊長會將 「沙田今日幾度?」歸類為「温度」類別。
最後, 聊天機械人會再進一步提取關鍵詞語(entities)內容去理解問題, 並準備答案。在這一例子中,「沙田」,「今日」 和「度」是分別是關鍵詞語「地方」、「時間」及「氣温」的內容。由於時間「今日」是一個時段, 所以度天隊長會去找當日沙田最高最低氣温的資料組織答案回答用戶(圖二)。
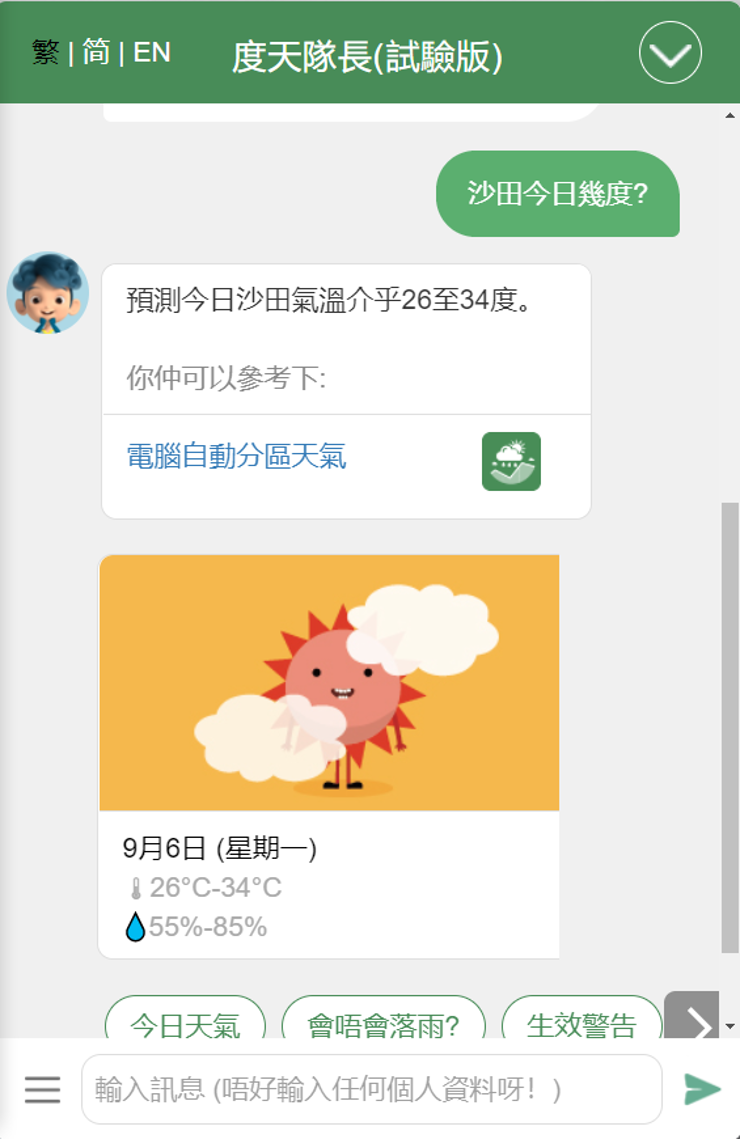
圖一:與度天隊長的一個對話實例
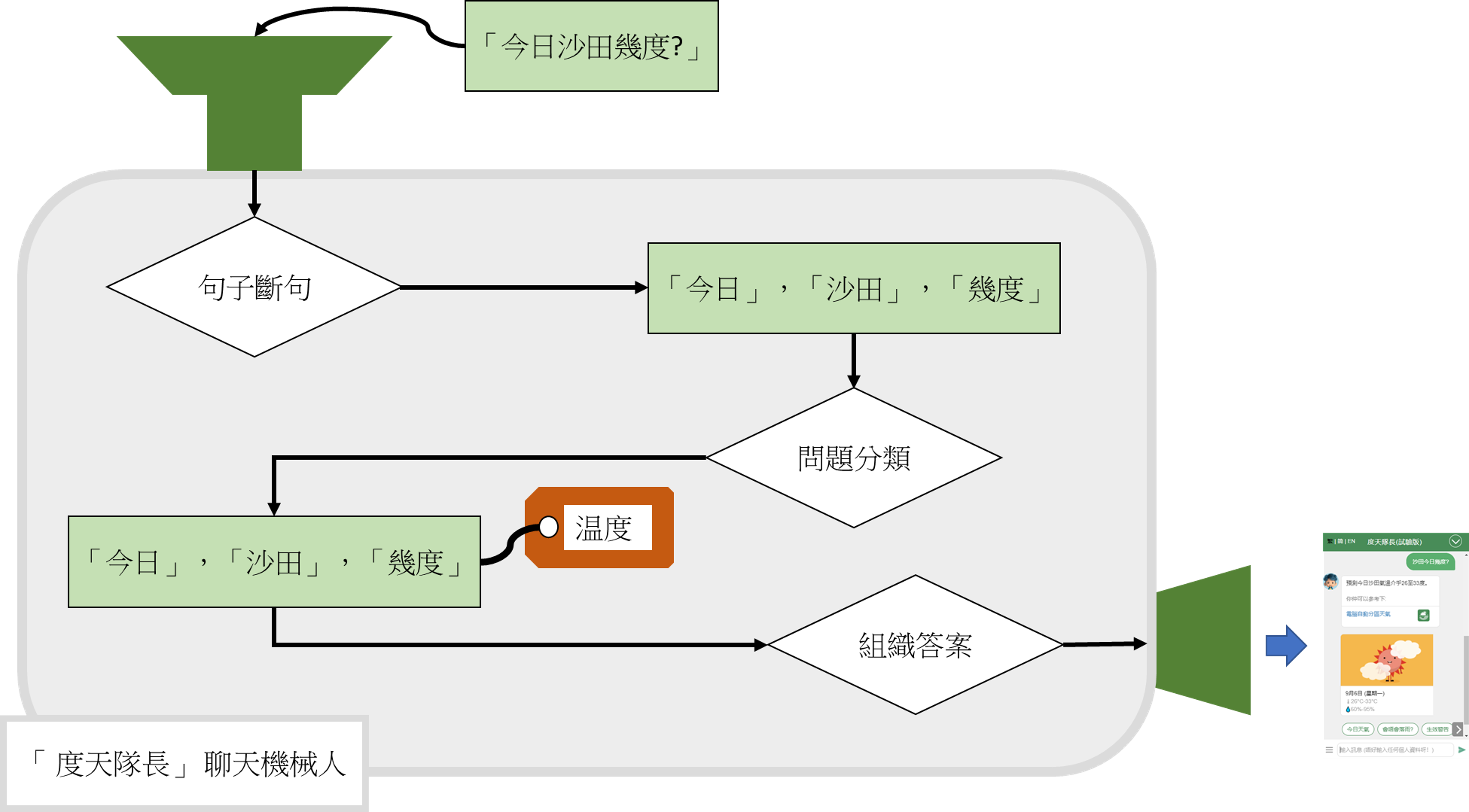
圖二: 聊天機械人的工作流程