A Deep Learning Journey of Chatbot “Dr Tin”
A Deep Learning Journey of Chatbot “Dr. Tin”
LAM Sam-yi
October 2022
Last time, we have talked about How Chatbot “Dr Tin” is Trained?.
After joining in the HKO team, “Dr. Tin” has been bothered by some “mysteries”.
Does “Your apple is broken!” mean the fruit is broken or an Apple phone is broken?
What does “No. 8 on Monday, No. 10 on Wednesday!” actually mean?
The field of deep learning is rapidly changing. “Dr. Tin” realises that it’s about time for a self-enhancement to improve his learning model.
Does “Your apple is broken!” mean the fruit is broken or an Apple phone is broken?
What does “No. 8 on Monday, No. 10 on Wednesday!” actually mean?
The field of deep learning is rapidly changing. “Dr. Tin” realises that it’s about time for a self-enhancement to improve his learning model.
Right now, when “Dr. Tin” receives a question from user, he will first tokenise the sentence, and match each token with a vector called “embedding” according to the language model used. An embedding vector consists of solely numbers. These numbers represent the “features” of the token, just as how each token has a “meaning” in linguistics.
Vectors can be visualised as arrows of different lengths and point at different directions. For tokens having similar meaning in linguistics, they should have similar vector representations. This means their arrows will be of similar length and direction. Vectors can be added or subtracted from each other. In ideal case, a perfect language model should be able to assign embedding vectors such that the below calculation is valid:
<king>-<man>+<woman>=<queen>
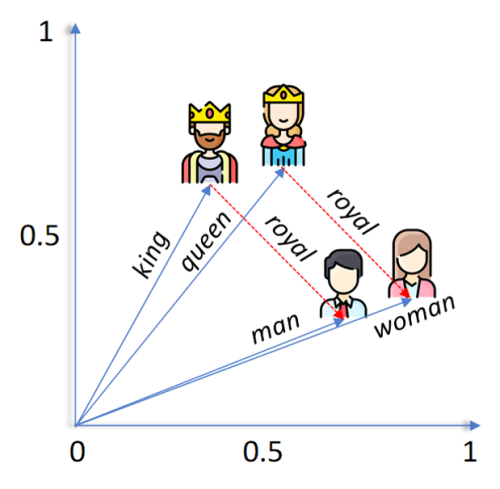
Figure 1 A schematic diagram of vector representations of “king”, “queen”, “man”, “woman” and “royal”.
Due to polysemy, the same word or token can have different linguistics meanings, and therefore different possible vector representations. So how could we identify the correct one? This is where the concept “attention” comes in handy.
Suppose a sentence is tokenised as the following:
Will / typhoon signal / 8 / be / issued / on / June / 8 / ?
The “8” at the end of the sentence has more relation with “June”, since they are both describing date and time. The “8” in the middle of the sentence, however, is more linked with “typhoon signal” and “issued”, because ... you know it.
So, in order to train a language model that can take these connections into consideration, “Dr. Tin” chose a training method called “Masked Language Modelling”. As the name suggested, a portion of the tokens in the sentence will be masked during training. The model is required to learn and calculate which other token(s) they should “pay attention” to, in order to deduce correctly what is being masked. For the below training set:
Will / typhoon signal / [MASK] / be / issued / on / June / 8 / ?
When / will / typhoon signal / [MASK] / be / issued / ?
Is / typhoon signal / [MASK] / issued / ?
The model would be able to learn that “typhoon signal”, “issued” and the word being masked (“[MASK]”) seems more related. (As for which typhoon signal is being issued...hmm.)
This is called “bidirectional encoder”, in which the tokens on both sides of the [MASK] token are used to determine the encoding of the [MASK] token. It is similar to how we read. To understand the meaning of a word in the sentence, you need to understand the sentence as a whole. After such training, the language model will be able to assign an embedding vector to each token that better represent its features and meaning in the sentence.
Which also means that “Dr. Tin” will be able to identify the meaning of “No. 8” in different context!
In other words, Masked Language Modelling is very similar to fill-in-the-blanks exercises. Deep learning is indeed computer algorithms developed by taking reference to human’s learning pattern. With a more localised or field-specific training dataset, “Dr. Tin” would be able to understand enquiries in localised or field-specific context better.
However, building a language model from scratch requires tens of millions of training sentences. The whole training process would take up to a week’s time to finish. In order to be cost-effective, “Dr. Tin” chose to do “fine-tuning” instead. There are plenty of open source pre-trained models online nowadays. These open source language models are trained with some big enough datasets beforehand, which give the models general knowledge on sentence structures, grammar or common vocabulary. “Fine-tuning” means to use these language models as basis to a train a fine-tuned model. Only a small amount of new training data of a specific field, such as Cantonese or meteorological terms, is needed for the model to learn some specific knowledge in a few hours. For example, building a new language model from scratch is like teaching an illiterate baby to understand this passage. “Fine-tuning” is like how you are reading this passage now.
In the journey, “Dr. Tin” also discovered many more deep learning methods that may train him to be an interactive voicebot. It would seem that using techniques similar to Masked Language Modelling may help to identify homophones or homographs too. Keep an eye on a smarter “Dr. Tin” on his continuous journey!