「度天队长」聊天机械人的深度学习之旅
「度天队长」聊天机械人的深度学习之旅
林沁宜
2022年10月
上回向大家解释了聊天机械人「度天队长」是如何炼成的,不知道大家还有印象吗?
自从我们的实习生「度天队长」投入工作以来,烦恼越来越多。
例如同事说「你只苹果坏咗啊!」到底是水果变坏,还是手机坏了?
又或者「星期一就8号,星期三呢就10号!」到底是在说日子,还是热带气旋警告信号呢?
深度学习的领域日新月异。「度天队长」发现,原来自己的判断模式依然有进步空间。
例如同事说「你只苹果坏咗啊!」到底是水果变坏,还是手机坏了?
又或者「星期一就8号,星期三呢就10号!」到底是在说日子,还是热带气旋警告信号呢?
深度学习的领域日新月异。「度天队长」发现,原来自己的判断模式依然有进步空间。
「度天队长」在收到输入的问题后,会首先将句子进行分词(tokenisation),然后根据电脑程式建立的语言模型(language model)为每一个词语配对上一个被称为embedding的向量(vector)。这些由纯数字组成的embedding就有如我们所认知的「词义」,代表著词语的「特征 (feature)」。
向量可以图像化成有不同长度、指向不同方向的箭头。假设意思相似的词语会有相似的embedding向量,箭头的长度方向也就越近似。由于向量有「可加可减机制」,极端来说,一个完美的语言模型能够做到以下的计算:
<国王>-<男人>+<女人>=<女皇>
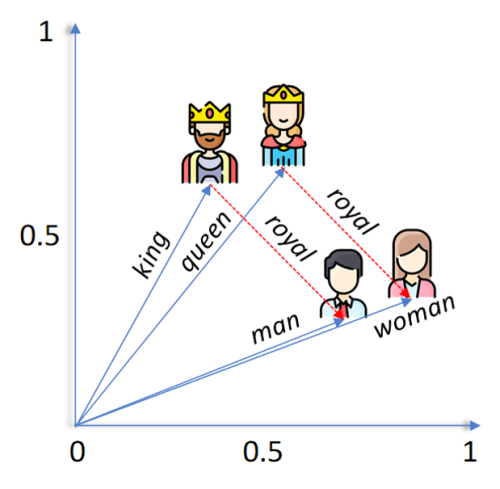
图一 国王(king), 女皇(queen), 男人(man), 女人(woman)及皇室(royal)的向量示意图。
要留意的是,在这个定义下,一个多义词就会有多个可能的embedding。那如何分辨到底是日历上的「8号」,还是台风天的「8号」呢?这时候,就需要深度学习中的一个概念:注意力(attention)机制。
假设「6月8号会唔会挂8号波?」这句句子被分词为:
6月 / 8号 / 会唔会 / 挂 / 8号 / 波 / ?
想知道前半的「8号」是甚么意思,就需要注意「6月」这个词语,因为他们都是形容日期或时间的。而后半的「8号」的词义则与「挂」和「波」这两个词语更有关系,因为...你懂的。
于是,为了训练一个可以反映出这些语意关联的语言模型,「度天队长」选择了名为遮蔽语言模型(Masked Language Modelling)的方法。顾名思义,这个训练方法会随机遮蔽固定比例的词语,然后计算同一句子中哪些词语对于推算被遮蔽的词语影响最大,需要投放更多「注意力」。 例如以下的训练集:
6月 / 8号 / 会唔会 / 挂 / [MASK] / 波 / ?
几时 / 挂 / [MASK] / 波 / ?
快啲 / 挂 / [MASK] / 波 / 啦 / !
就可以令模型学习到「挂」和「波」这两个字对推断被[MASK]遮蔽的词语的embedding更有用,亦代表这些词语的意思更有关连。(至于到底挂几号波...嗯。)
而这种将目标词语前后的文字都纳入计算范围的模式被称为双向编码器(bidirectional encoder),也可以想像为我们所谓的前文后理。经过训练后的语言模型,就可以根据整体的句子或文章,为分词后的词语配上更能准确代表其特征的embedding。对「度天队长」来说,就是他终于学会在不同前文后理的情况下,「8号」到底是哪个意思了。
其实换个角度解释,遮蔽语言模型和填充题很类似。深度学习就是参考了人类的学习模式而发展的电脑演算法。也就是说,「度天队长」需要更加「贴地」的训练集,才能更好的理解用户的查询。
可是,重头建立一个语言模型,动辄需要几千万的句子用作训练,甚至可能要电脑运算超过一个星期。为了节省成本和时间,「微调(fine-tuning)」就成为了一个很好的选择。 现在网络上有很多开源(open source)的预训练模型(pre-trained model)。这些语言模型以大量的数据集预先训练好,对一般的句式、文法等一个有「基础理解」。微调则是以这些预训练模型作为基础,只需要使用少量的训练集,就可以在几个小时内使模型学习到一些更专门的语法或词语,例如广东话和天文气象的专有名词。 打个比喻,如果重头训练语言模型就像教只字不识的婴儿读这篇文章,那微调就像是你现在在读这篇文章一样。
在旅途中,「度天队长」更发现有许多不同的深度学习方法,能训练他成为可以对话的语音机械人。说不定,如果用上和遮蔽语言模型类似的学习方法,还可以让他分辨同音字和多音字呢。 希望这场深度学习之旅早日修成正果,让大家一起见证「升呢」的「度天队长」!