Characteristics of Meteorological Databases
Characteristics of Meteorological Databases
CHENG Tsz-lo
August 2017
Hong Kong has a very dense weather observation network despite its relatively small geographical area (Figure 1). More than 300 automatic weather and rainfall stations were set up by the Hong Kong Observatory (HKO) and other government departments over some 1,100 square kilometers of land in Hong Kong [1]. As automatic weather stations generally measure a number of weather elements simultaneously, more than 2,500 weather observation data are transmitted from different parts of the territory to the Observatory via communication networks at one-minute intervals. These raw data are stored in one of Observatory’s databases for handling weather observations from local and neighbouring areas after pre-processing. They are one of the vital sources for the compilation of weather reports and generation of forecast products.
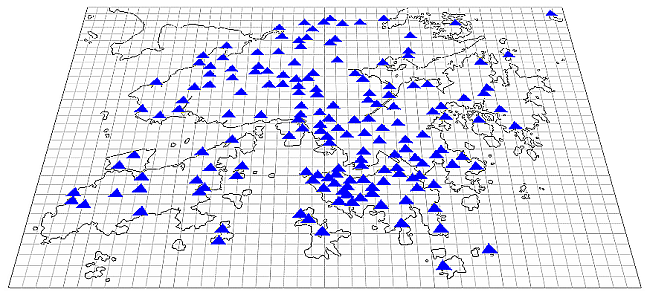
Figure 1 A very dense weather observation network covering Hong Kong.
Perhaps you may ask: Why a sophisticated database system is required to handle data with an incoming rate of less than 3,000 records per minute? In fact, these records will be extracted from the database and modified a number of times during the analysis and quality assurance processes. Some 20,000 sets of derived data and products so generated will also be stored in the database. As a result, the workload to process these data multiplies rapidly in a short period of time. Moreover, data and products are extracted from the database by dozens of applications to generate meteorological reports and forecast bulletins. Other than local data, the database also processes and stores huge amounts of meteorological data from nearby areas. Hence, the Observatory needs to employ highly efficient databases to handle the vast volume of weather data.
To facilitate weather analysis and diagnosis by meteorological personnel, technical support staff will strive to provide them with meteorological data with the same observation time for reference. The weather elements collected from all weather stations are thus transmitted to the Observatory’s database in real time, requiring the database for handling a large volume of raw, derived and product data within tens of seconds. After the peak, the workload of the database will reduce significantly until the next data collection cycle. In other words, prominent differences in the workload can be seen during different time periods in a data collection cycle (Figure 2). Meteorological database needs to deal with this explosive data surges, which is rather different from the daily operation of general office database. Weather database thus demands for more proficient operational performance than general office database in order to avoid data loss and delay.
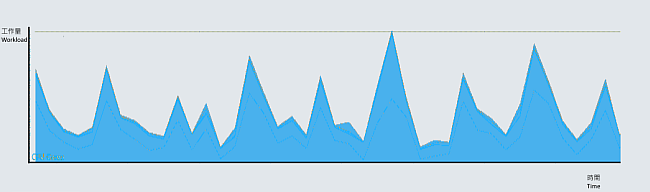
Figure 2 Schematic diagram of time variation of the workload of a meteorological database, showing the characteristics of significant differences in the workload in a data collection cycle.
Fluctuations in the workload of a meteorological database are in fact not uncommon for a database of financial market. The major difference between the two probably is that weather is non-stop and round-the-clock, whereas financial markets have non-operating hours. Global financial markets operated in different time zones are tightly connected, but still not comparable to the systems handling global weather data. In the meteorological world, data are running “7 x 24”. Identifying a certain time interval for database maintenance is not an easy task. Therefore, the hardware and software requirements of a meteorological database are much more stringent in terms of their availability and capability in disaster recovery. With rapid development of science and technology, more and more advanced database technologies become available. The Observatory will continue to strive to deploy advanced and appropriate technologies to provide reliable services to the public.
Reference:
[1] Hong Kong in Figures
[1] Hong Kong in Figures